mardi 13 mars 2012
Big data est une expression qui s’est imposée ces deux ou trois dernières années et est utilisée (source : Wikipedia) pour désigner des ensembles de données qui deviennent tellement gros qu'ils en deviennent difficiles à travailler avec des outils classiques de gestion de base de données. Dans ces nouveaux ordres de grandeur, la capture, le stockage, la recherche, le partage, l'analyse et la visualisation des données doivent être redéfinis. Cette définition un peu triviale décrit notamment un phénomène qui se produit sous nos yeux et qui est rendu possible grâce aux technologies qui sont désormais disponibles et permettent de faire aujourd’hui ce qui n’était envisageable il y a encore peu de temps.
« Pour les entreprises, le big data offre des opportunités importantes pour améliorer l’efficacité opérationnelle et générer de l’innovation,considère Dan Vesset, vice president Business Analytics Solutions d’IDC. Des cas d’utilisation existent déjà dans de nombreux secteurs et zones géographiques ». Rappelons d’ailleurs que l’analytics dont le big data est une composante de plus en plus importante est la première préoccupation technique des DSI en 2012 selon le Gartner. Du côté de l’offre, les grands fournisseurs se mobilisent sur ce nouveau sujet, mais de nombreuses startups se créent. A ce jour, plus de 500 millions de dollars ont été investis par le capital-risque dans la création de jeunes pousses spécialisées dans le big data.

Cette croissance moyenne du marché de 40 % se répartit différemment en fonction des différentes composantes et s’établit comme suit : 27 % pour les serveurs, 34 % pour le logiciel et 61 pour le stockage. Cela montre d’ailleurs que big data correspond à l’idée d’important volume de données qu’il fut bien stocker quelque part.
Dans l’étude intitulée Worldwide Big Data Technology and Services 2012-2015 Forecast qu’il publie, le cabinet IDC organise les projets en trois scénarios :
- Ceux dont le volume des données collectées dépasse les 100 To. IDC utilise à dessein le terme « collecté » au lieu de « stocké » pour indiquer qu’il s’agit d’utilisation en priorité des technologies in-memory dans lesquels les données ne sont pas stockées sur un disque ;
- Des projets utilisant des technologies de messaging ultra-rapide où les données sont capturées en temps réel et en streaming. Ce scénario correspond au « big dat in motion » par opposition à « big data at rest ».
- Des déploiements où le volume de données n’est pas encore très important, mais qui croît à un rythme très rapide de plus de 60 % par an.
Hadoop, MongoDB, Cassandra et les autres…
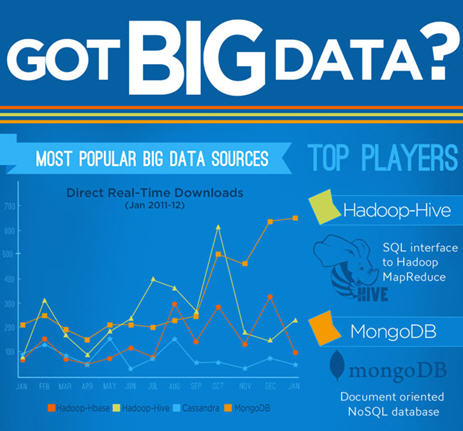
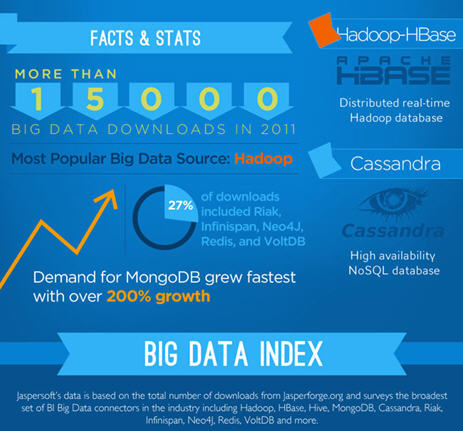
Le big data nécessite des technologies nouvelles dont hadoop est sans doute une des plus connues (Comprendre hadoop en moins de 5 minutes). L’éditeur Jaspersoft, vient de publier un indice Big Data dans le secteur du décisionnel, un classement des connecteurs en téléchargement associés aux principales bases et sources de données, notamment Hadoop Hive, Hadoop HBase, MongoDB, Cassandra, et autres infrastructures largement utilisées pour gérer les ensembles Big Data.
Sur la base des données de téléchargement enregistrées entre janvier 2011 et janvier 2012, Jaspersoft peut évaluer les tendances de croissance pour l’analyse Big Data de manière générale et effectuer un classement de la demande pour chaque source de données.
Selon l’indice Big Data de Jaspersoft, on a observé l’année passée une nette augmentation de la demande pour des méthodes plus rapides et plus transparentes permettant de se connecter, d’analyser et de présenter les informations extraites des Big Data. Ces données reposent sur le nombre total de téléchargements de connecteurs sur JasperForge, le site Web communautaire open source de Jaspersoft. L’indice Big Data englobe un très vaste ensemble d’environnements NoSQL et Big Data, dont Hadoop Hive, Hadoop HBase, MongoDB, Cassandra, Riak, Infinispan, Neo4J, Redis, CouchDB, VoltDB, etc.
« L’extraction rapide d’informations pertinentes des sources Big Data telles que Hadoop ou MongoDB procure aux entreprises un immense avantage concurrentiel », explique Karl Van den Bergh, vice-président Produits et alliances chez Jaspersoft. « Grâce à l’indice Big Data, nous pouvons dégager trois approches communément utilisées pour accéder aux environnements Big Data dans un cadre décisionnel. Il s’agit du reporting et de l’analyse via une connectivité directe, du reporting direct par lots et de l’extraction de données via ETL par lots vers une base de données ou un entrepôt central ».
Source: infoDSI.com
http://www.infodsi.com/articles/130141/decollage-big-data.html?key=
Aucun commentaire:
Enregistrer un commentaire